Neural Stochastic Optimal Control
Problem statement
Numerical optimal control solvers efficiently compute locally optimal trajectories given smooth and differentiable objective functions. Conversely, RL approximates general policies while using sampling to relax differentiability requirements on the objective.
Aim. Formulate a global method that uses sampling to handle discontinuities inspired by RL while preserving efficiency and generalisation.
Continuous stochastic Bellman equation
In this case, we use the stochastic HJB equation.
Optimal controls. Assuming affine control \(d\vec x_t=\left(\vec h\left(\vec x_t\right)+\vec g\left(\vec x_t\right)\vec u_t\right)\,dt+\vec B\left(\vec x_t\right)\,d\vec w_t\) and quadratic control cost, we can analytically solve for \(\vec u_t\):
Our optimal control remains the same, and so does our choice of parameterisation: the value function.
Learning the value function
As in the deterministic case, we define a constraint on the expected rate of change of value function.
Intuition. Under policy \(\vec u_t^*\), the expected change in value equals the negative cost rate in expectation.
TD(ish) view
Satisfying this constraint over horizon \(N\) can be viewed through an update analogous to TD.
Note. We cannot simply sum costs backwards because of the expectation under \(\mathcal Q\).
Gradient computation
Stochastic adjoints are costly here, so we reparameterise the Euler-Maruyama step with Gaussian noise, approximate the expectation by Monte Carlo, and backpropagate through the sampled rollout.
Intuition. Noise is sampled, not differentiated; gradients flow through the sampled next state and the Bellman residual.
Discrete algorithm
Initialize: x(0)=x0, Δt, N=T/Δt, EQ[v(xN,N)] = EQ[ψ(xN)] For i = 0 ... N−1: ui = −(∇²u_i lctrl(ui))−1 g(xi)T ∇x ṽ(xi, i; θ)T xi+1 = xi + ( h(xi) + g(xi)ui ) Δt + B(xi) εi √Δt Optimize: minθ Σi=0..N ( ṽ(xi, i, θ) − EQ[ṽ(xi+1, i+1, θ)] − l(xi, ui*) Δt )2
Intuition. Roll out trajectories under the current optimal policy, then fit the stochastic Bellman residual.
Results
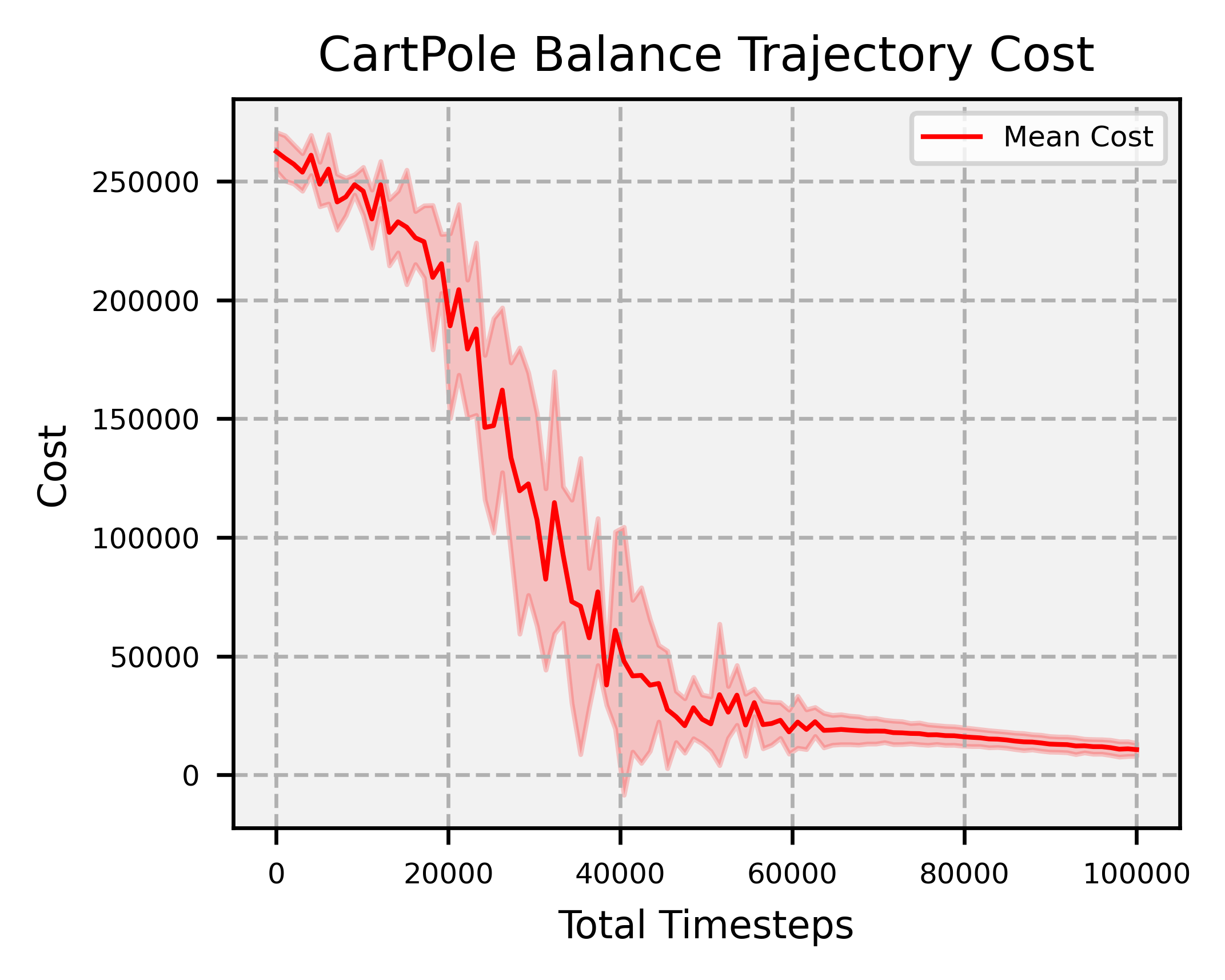
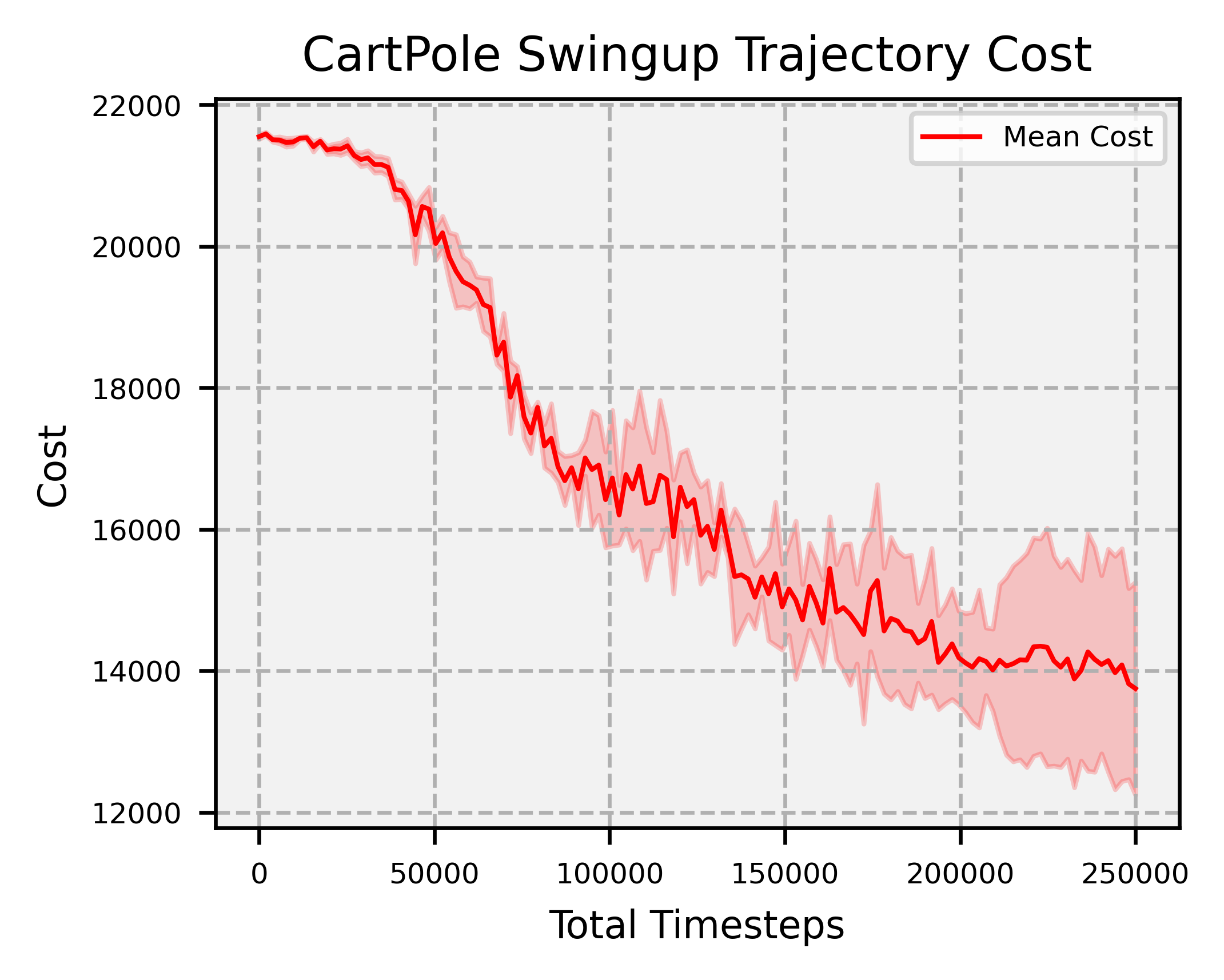
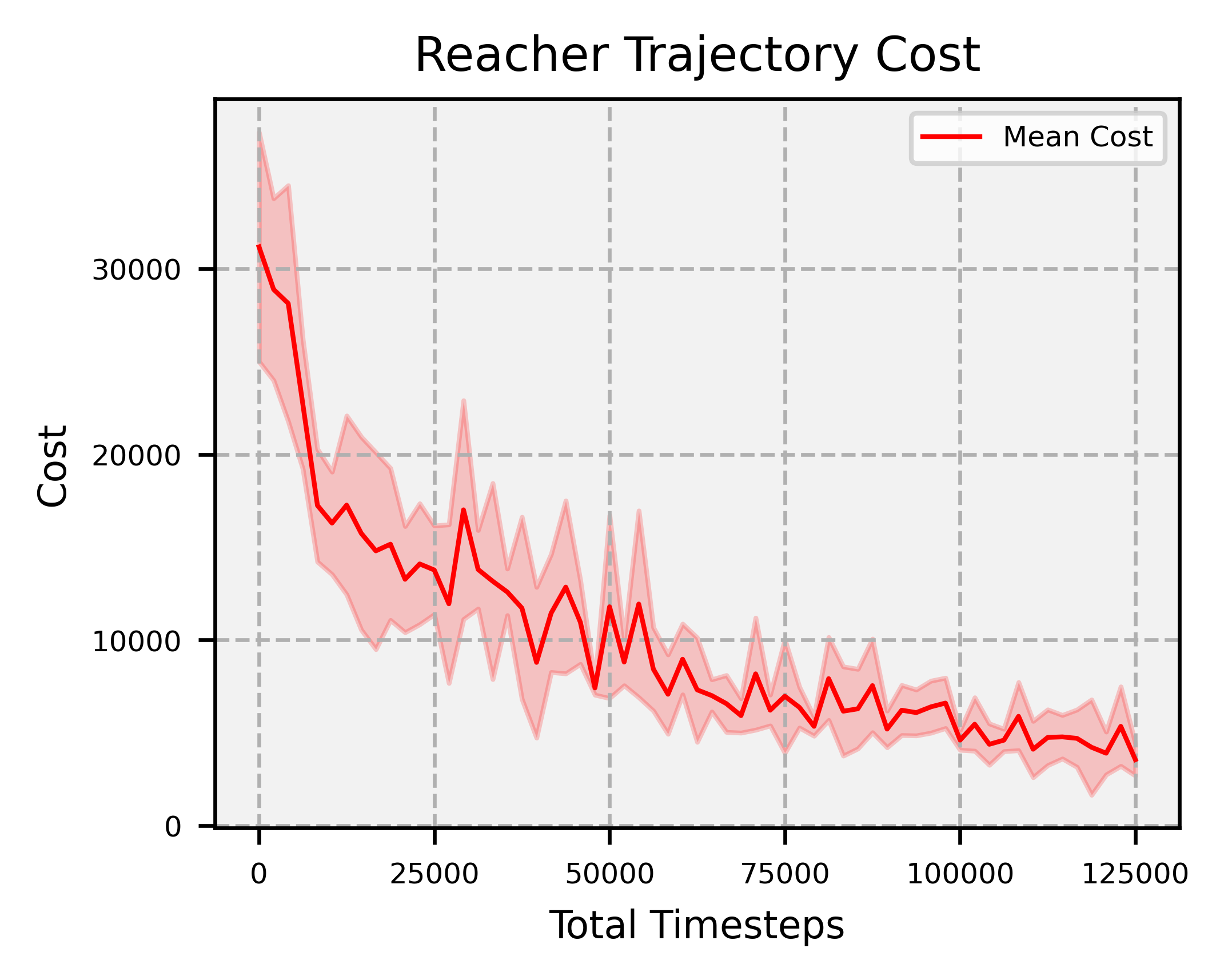
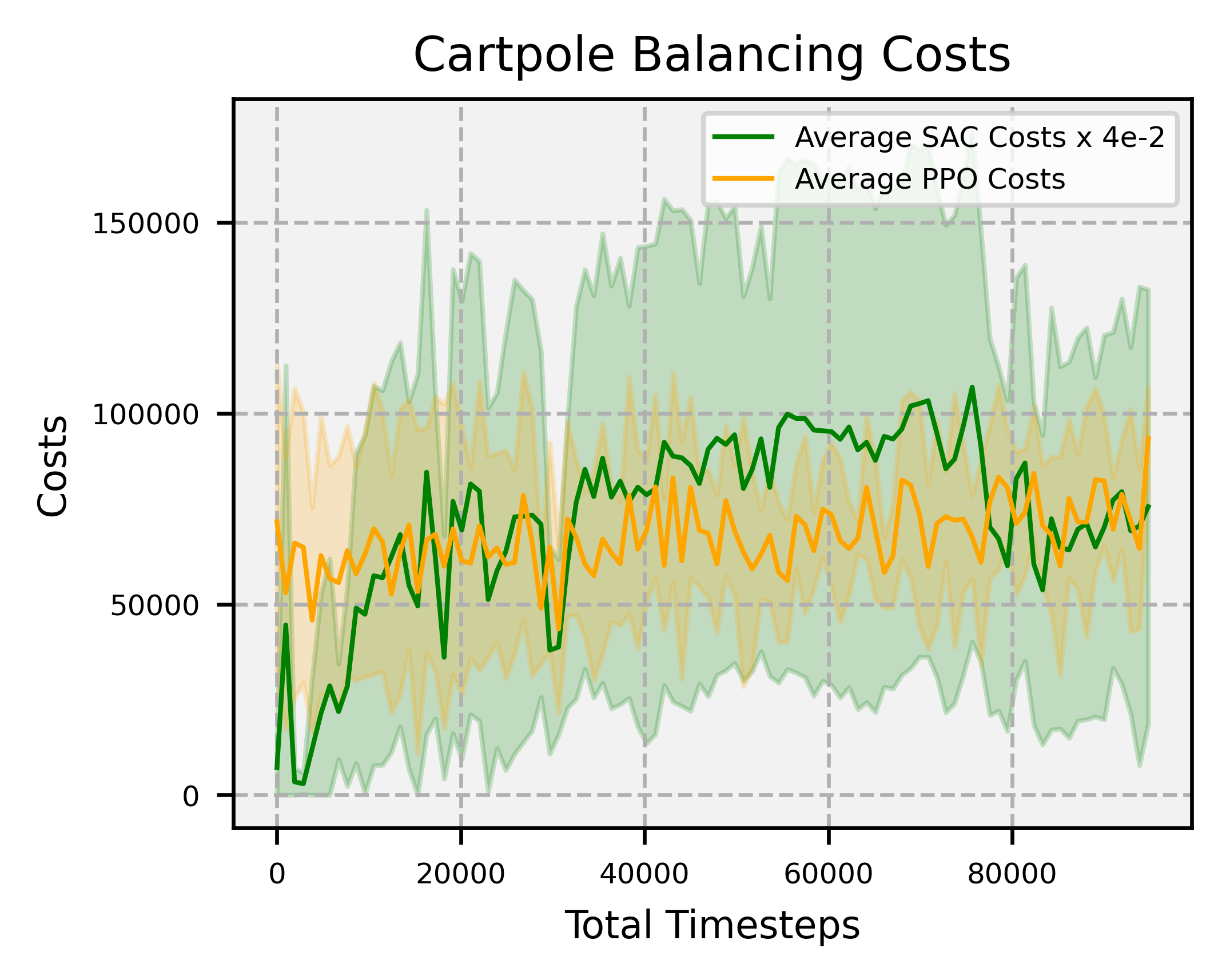
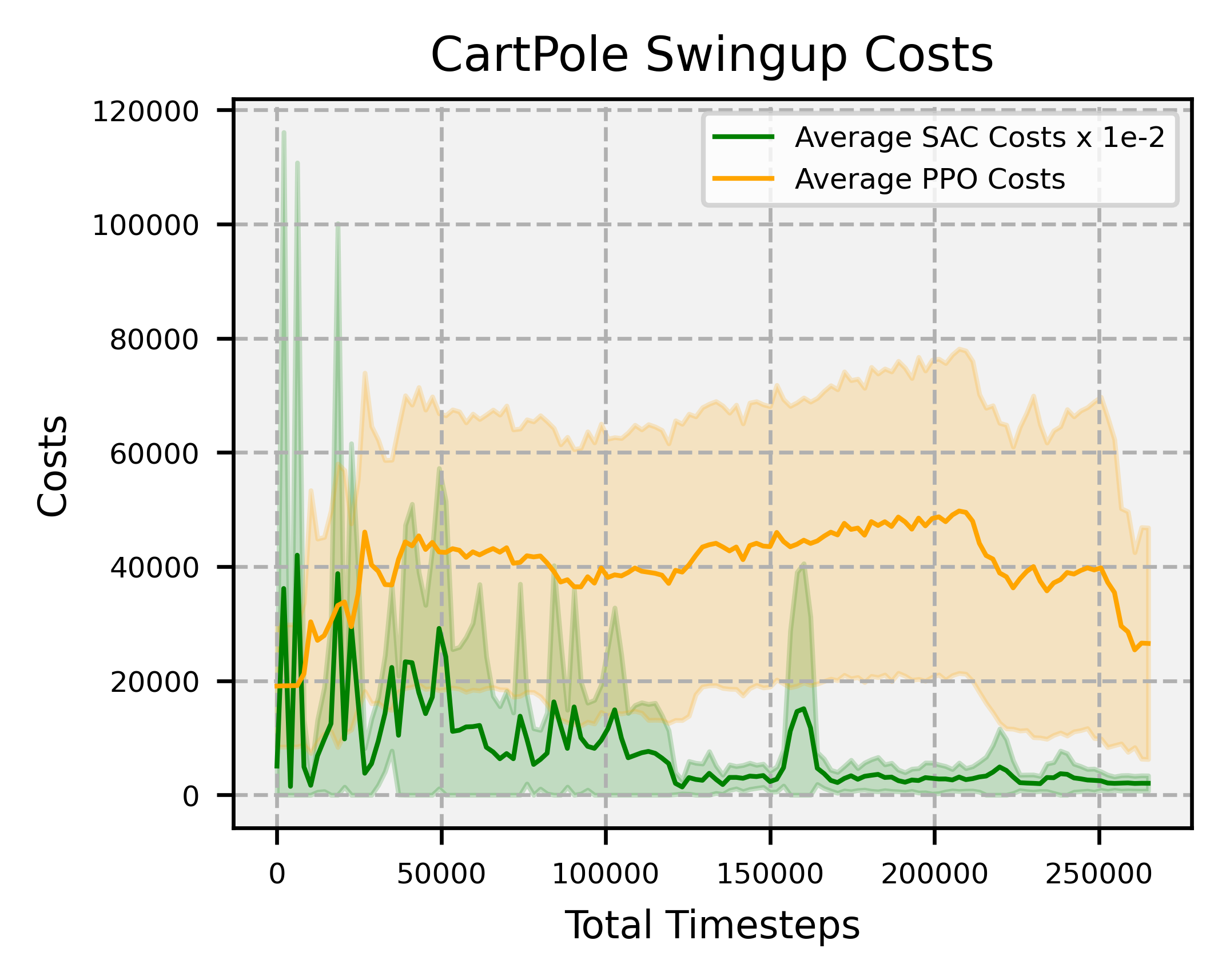
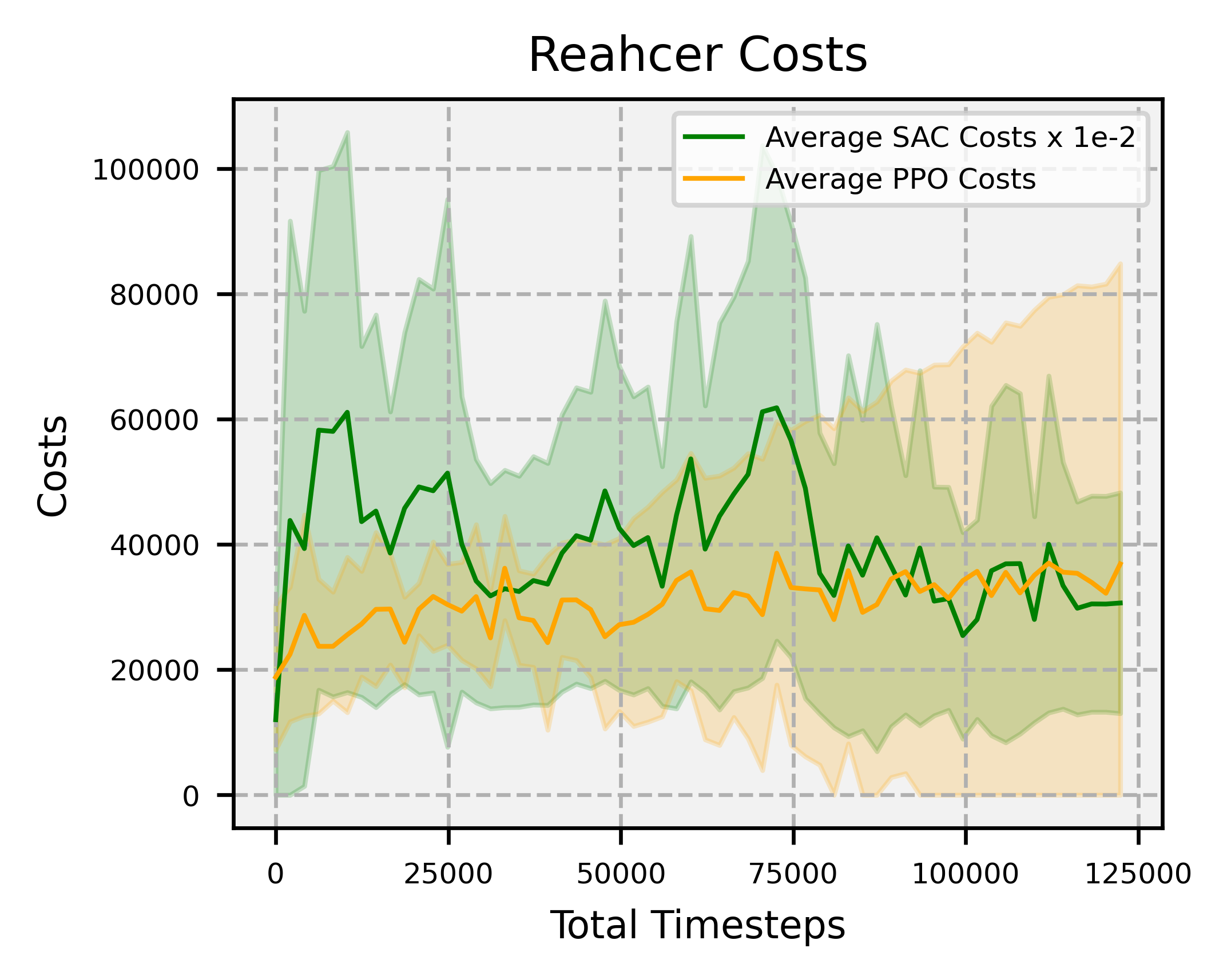
Overview: significantly faster convergence and lower variance across random seeds, outperforming SAC and PPO by at least factors of 18 and 2, respectively.
Noise-driven smoothing (Obstacle avoidance with discontinuous objective)
Value learning under stochastic dynamics and discontinuous objectives.
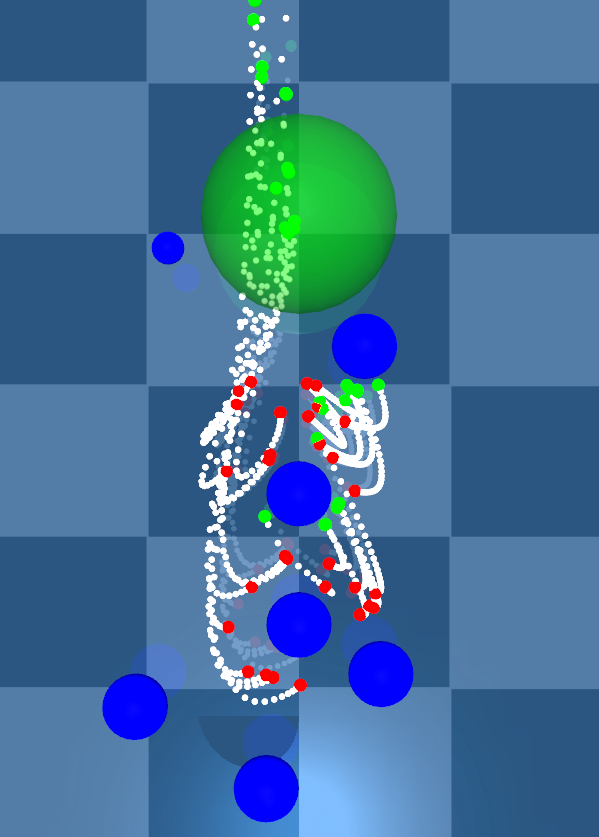
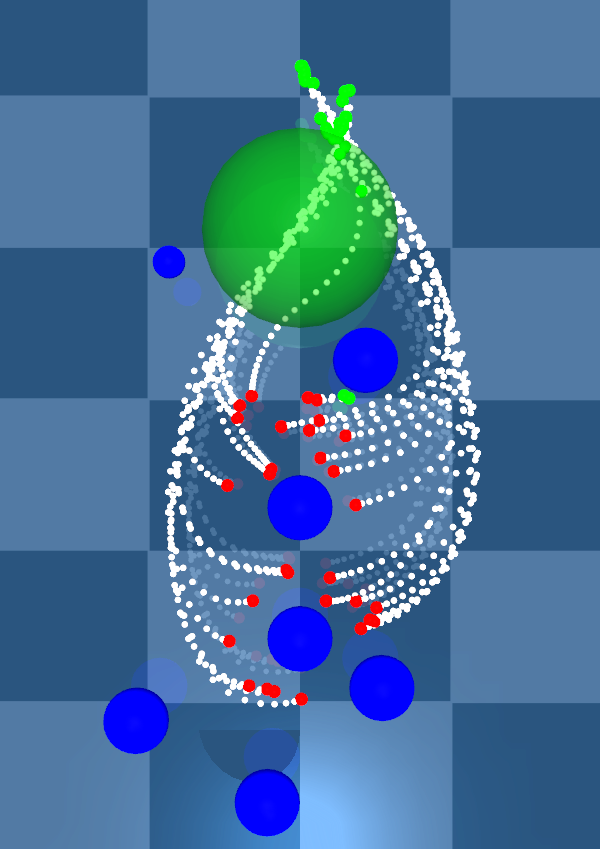
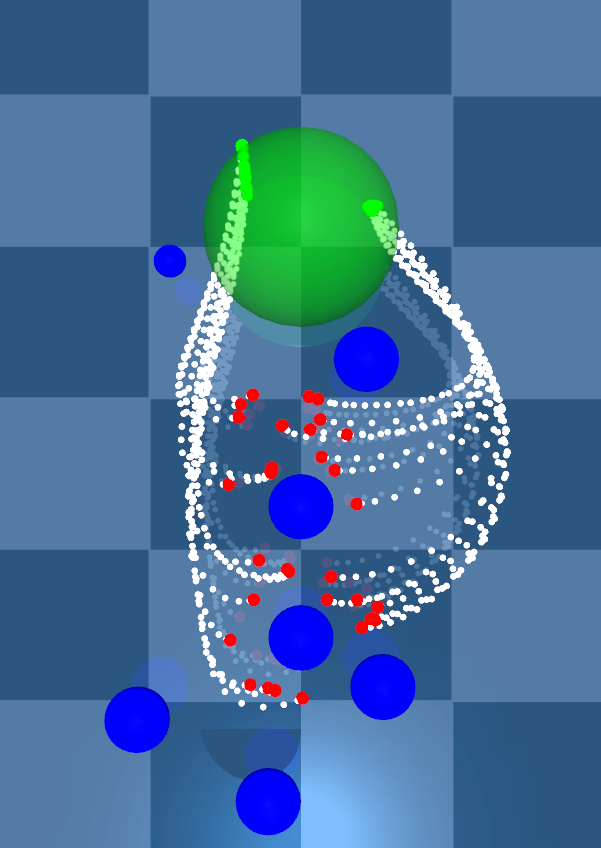
Higher noise regularises the value function through the curvature term \(\operatorname{trace}\left(\nabla^2_{\vec x_t\vec x_t}v\left(\vec x_t,t\right)\vec\Sigma\left(\vec x_t\right)\right)\).
As we increase the control noise samples move trajectories farther from obstacles. This is evidence that noise regularises value function curvature, improving robustness.
Conclusion
Contribution
- Global policy.
- Robustness to discontinuities via noise.
- Faster convergence.
Caveats
- Requires full dynamics information.
- SDE rollouts are substantially more memory-intensive.