Neural Lyapunov and Optimal Control
Problem statement
Numerical optimal control solvers parameterise trajectories to provide locally optimal solutions given smooth and differentiable objective functions. Conversely, RL parameterises function space to synthesise approximate global policies.
Aim. Combine the generalisation capabilities of RL with the efficiency of OC theoretic solutions by leveraging differentiation for efficiency and function-space parameterisation for generalisation.
Optimisation in RL
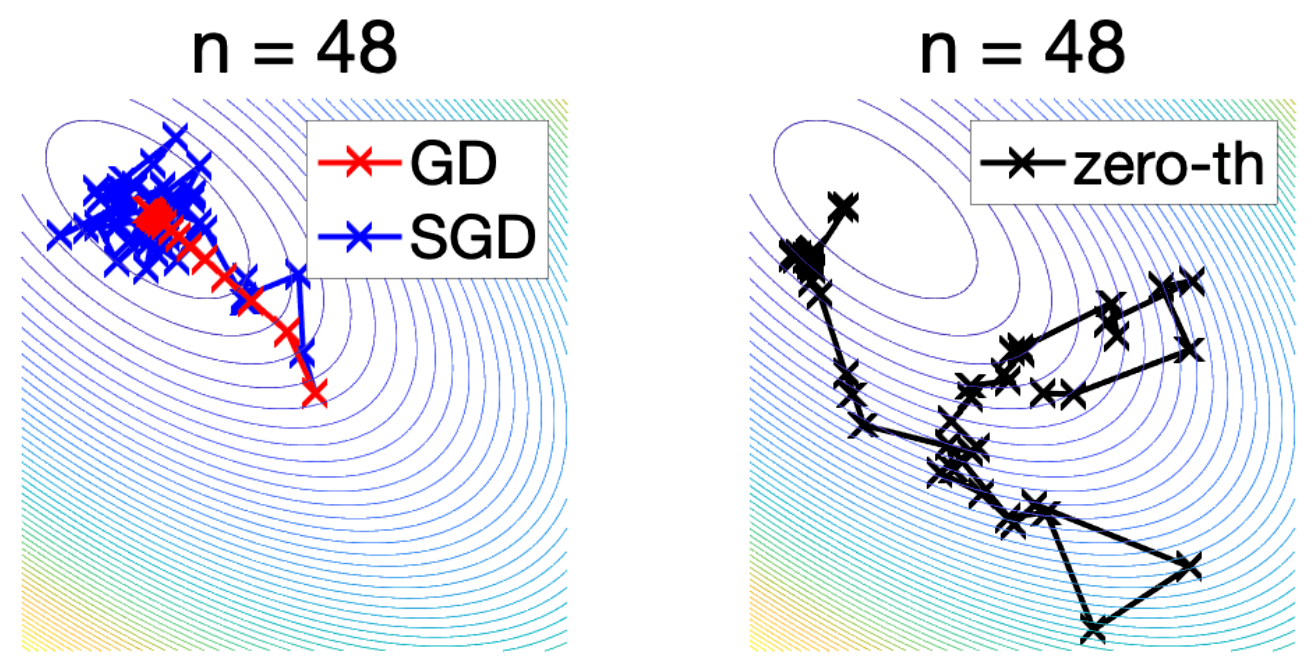
Famous RL environments
RL environments tinker with dynamics tuning under the hood.
Continuous Bellman equation
Our approach relies on the Hamilton-Jacobi-Bellman equation.
Optimal controls. Assuming affine control \(\dot{\vec x}_t=\vec h\left(\vec x_t\right)+\vec g\left(\vec x_t\right)\vec u_t\) and quadratic control cost, we can solve analytically:
This computes the optimal greedy control given the optimal value function, motivating value-function parameterisation.
Local solutions
Pontryagin's minimum principle is the classical local trajectory-space solution and the basis for methods such as DDP and iLQR.
Initial condition: \(\vec x=\vec x_0\in\mathbb{R}^m\). Terminal condition: \(\vec p\left(T\right)=\nabla_{\vec x_T}\psi\left(\vec x_T\right)^\top\).
PMP
Solve one ODE forward for \(\vec x(t)\) and one backward for \(\vec p(t)\).
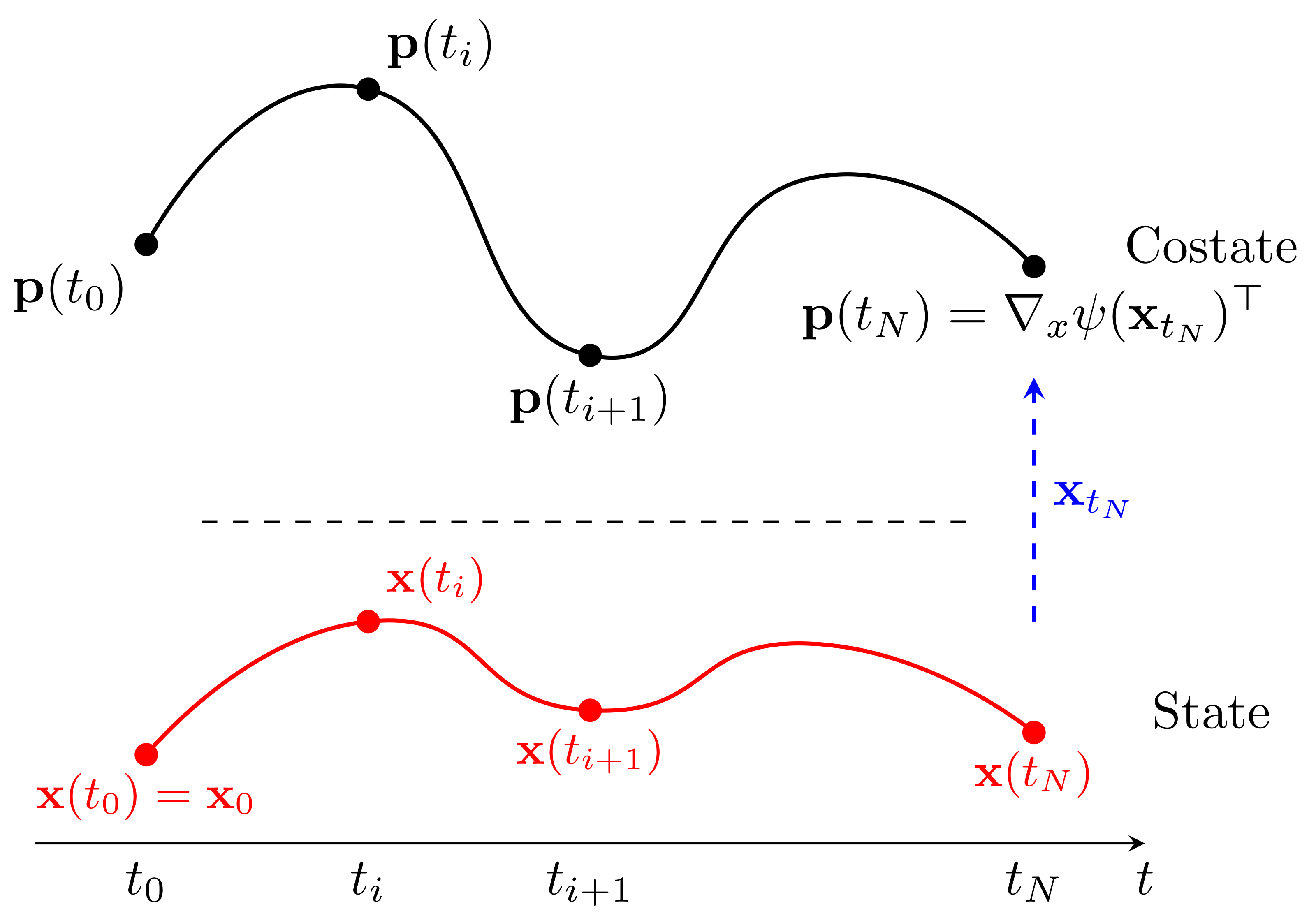
Making PMP global
Rearranging HJB gives a concise constraint on the rate of change of the value function:
Intuition. Under policy \(\vec u_t^*\), value decreases at a rate negative to cost.
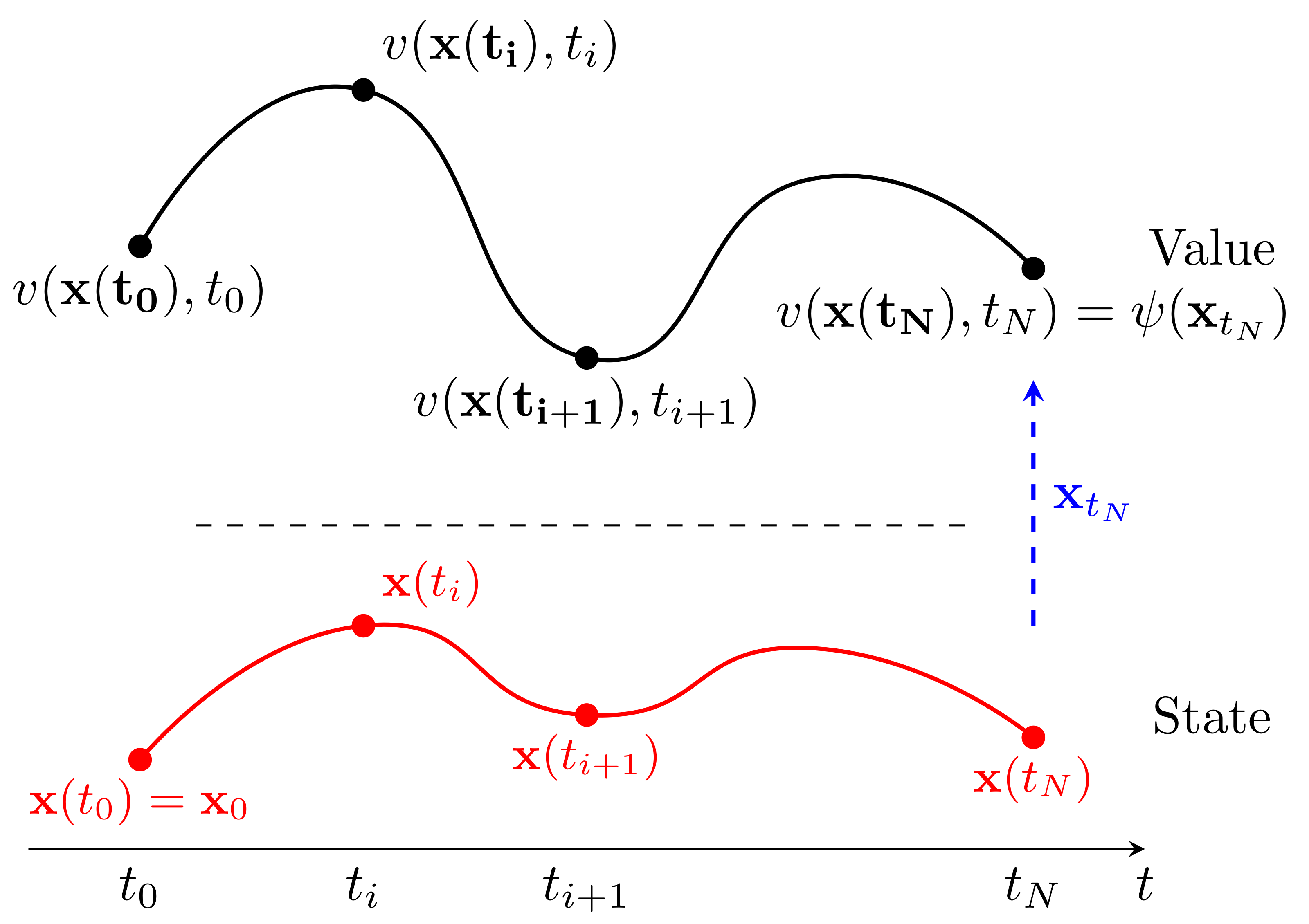
Making PMP global (parameterised value function)
Parameterise \(v\left(\vec x_t,t;\theta\right)\) directly to learn an approximate global value function and therefore policy.
Initial: \(\vec x=\vec x_0\in\mathbb{R}^{B\times m}\). Terminal: \(v\left(\vec x_T,T;\theta\right)=\psi\left(\vec x_T\right)\).
Dynamic programming view
The discrete solution resembles a dynamic programming update:
Intuition. Essentially a cumulative sum of costs backwards.
Global PMP
Solve one ODE forward for \(\vec x\left(t\right)\) and backwards for \(v\left(\vec x\left(t\right),t\right)\).
Gradient computation
Naively, learning would require backpropagating the running cost through the full rollout. Instead, we summarize future cost sensitivity with a continuous adjoint and avoid explicit discrete BPTT.
Intuition. Rather than backpropagating through every timestep, the adjoint carries the effect of future running costs backward through the dynamics.
Discrete algorithm
Initialize: x(0)=x0, Δt, N=T/Δt, v(xN, N)=ψ(xN) For i = 0 ... N−1: ui = −(∇²u_i lctrl(ui))−1 g(xi)T ∇x ṽ(xi, i; θ)T xi+1 = xi + f(xi, ui) Δt For i = N−1 ... 0: v(xi, i) = v(xi+1, i+1) + l(xi, ui) Δt Optimize: minθ Σi=0..N ( v(xi, i) − ṽ(xi, i, θ) )2
Intuition. A fitted value iteration pattern: rollout, compute values, fit to targets.
Results
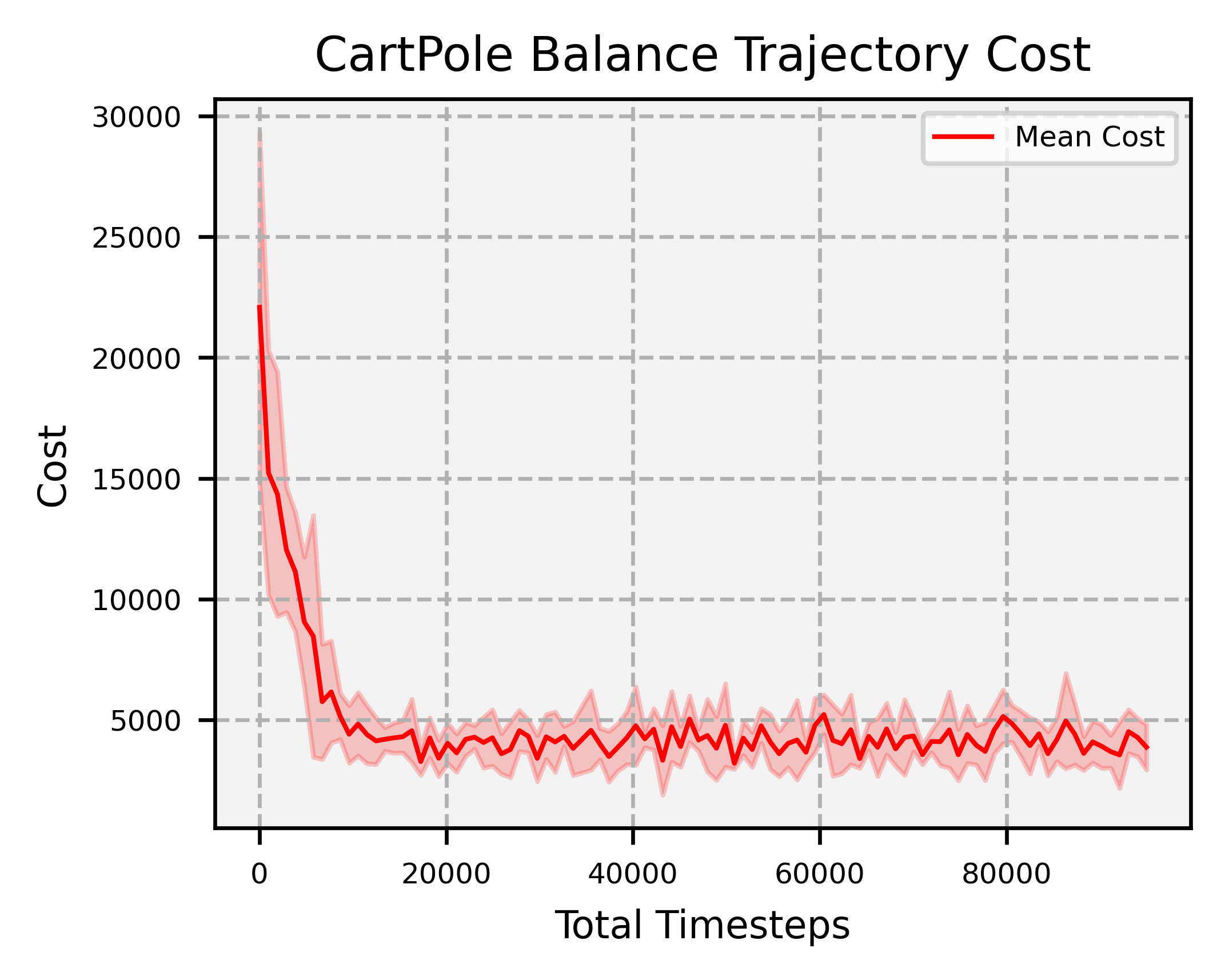
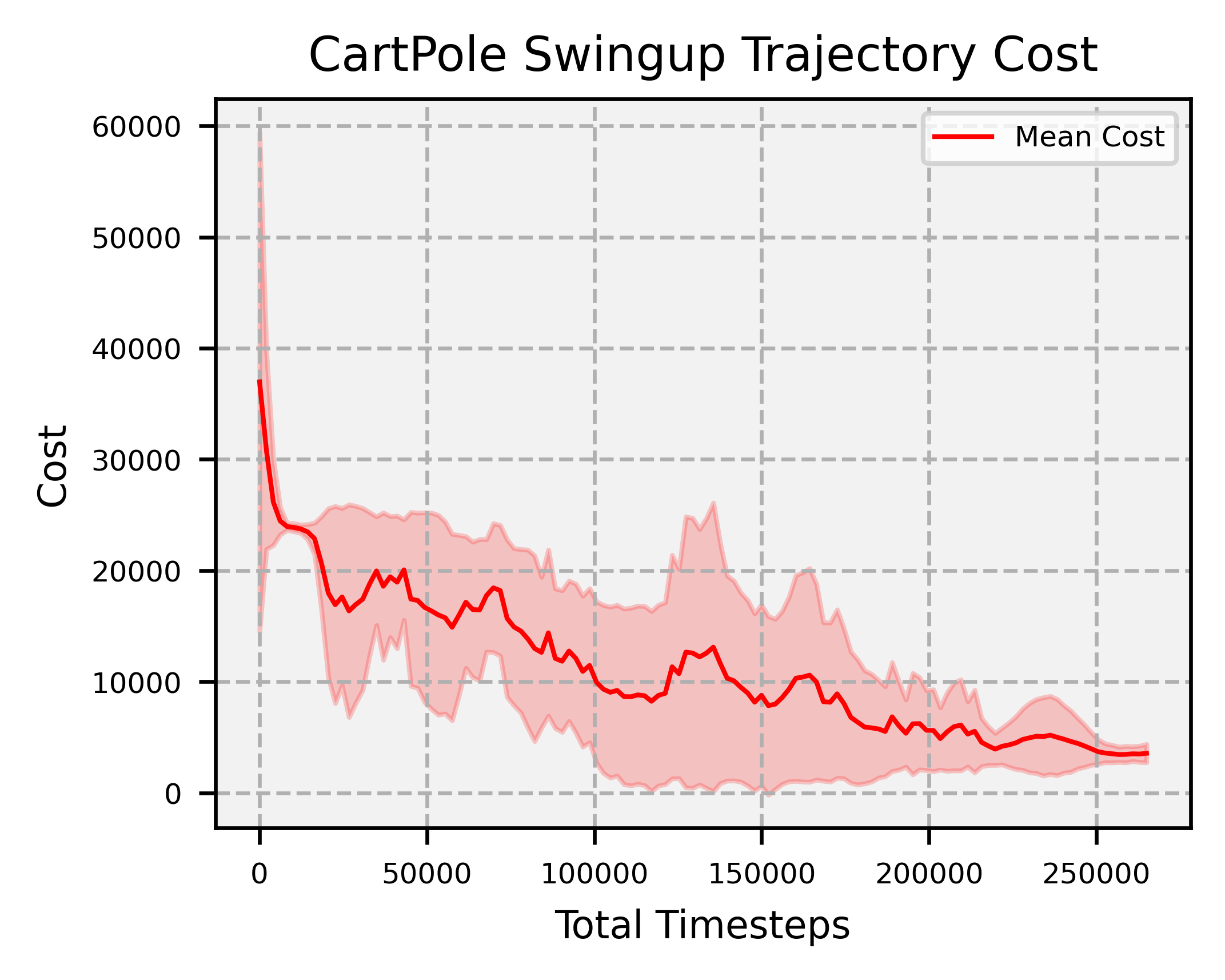
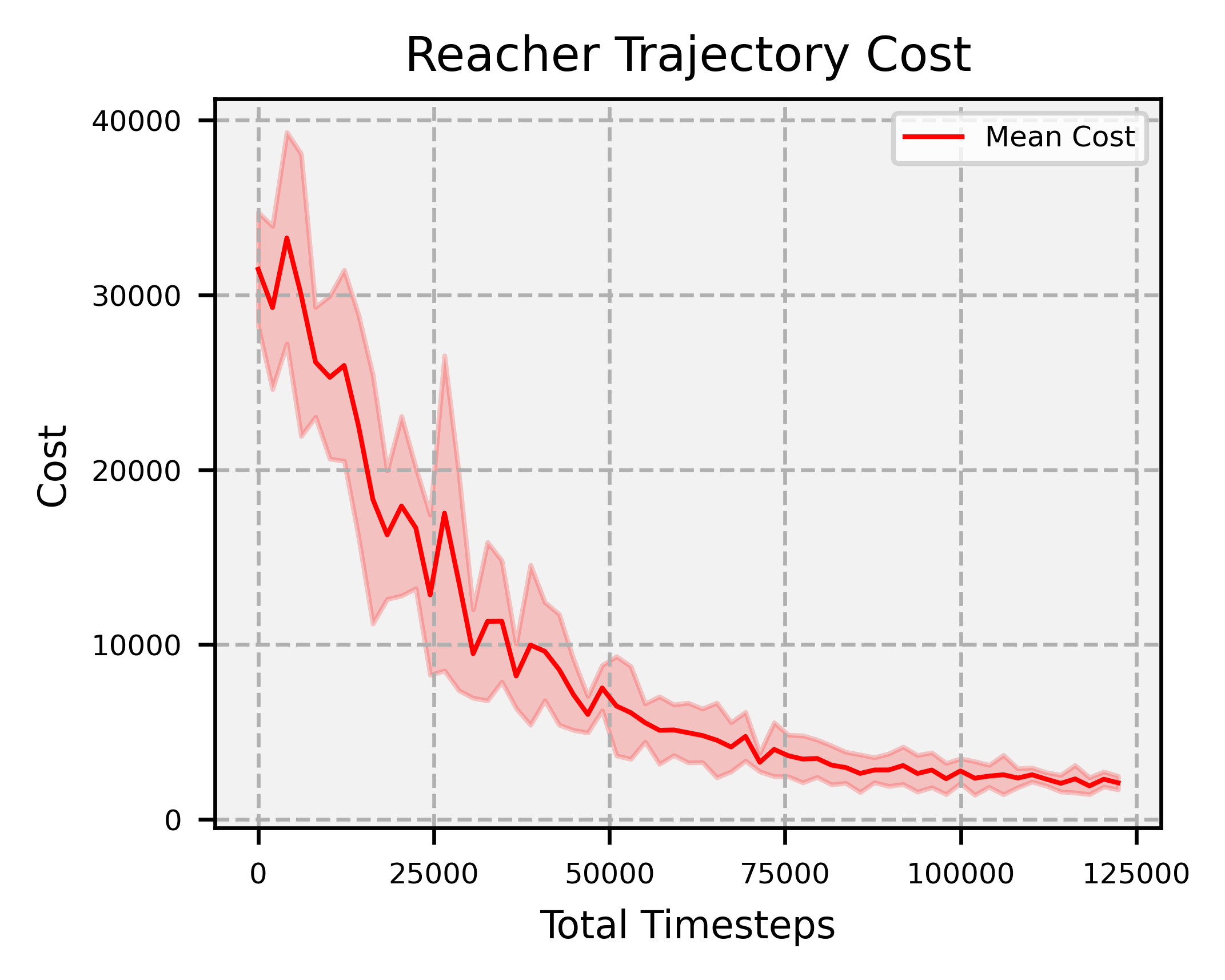
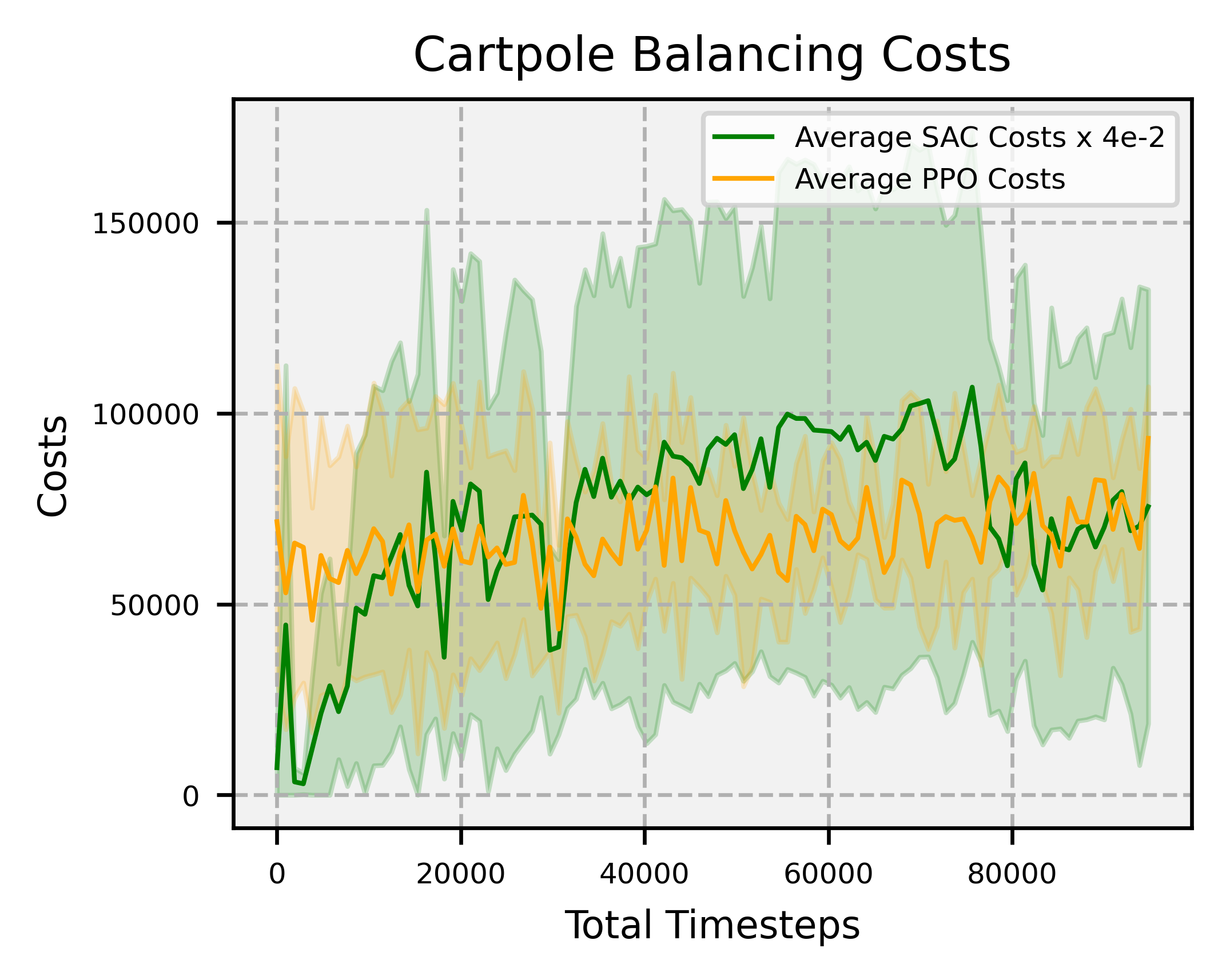
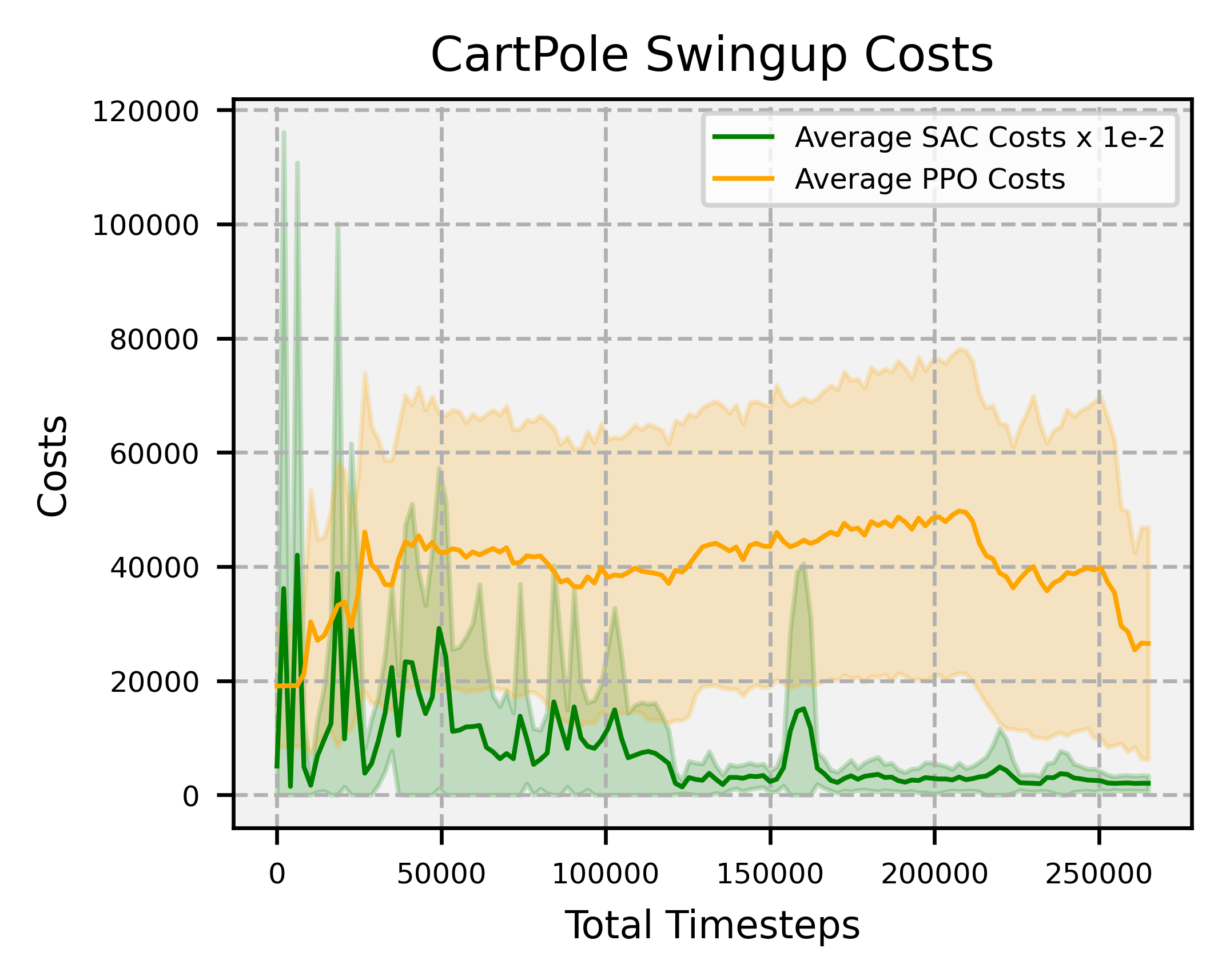
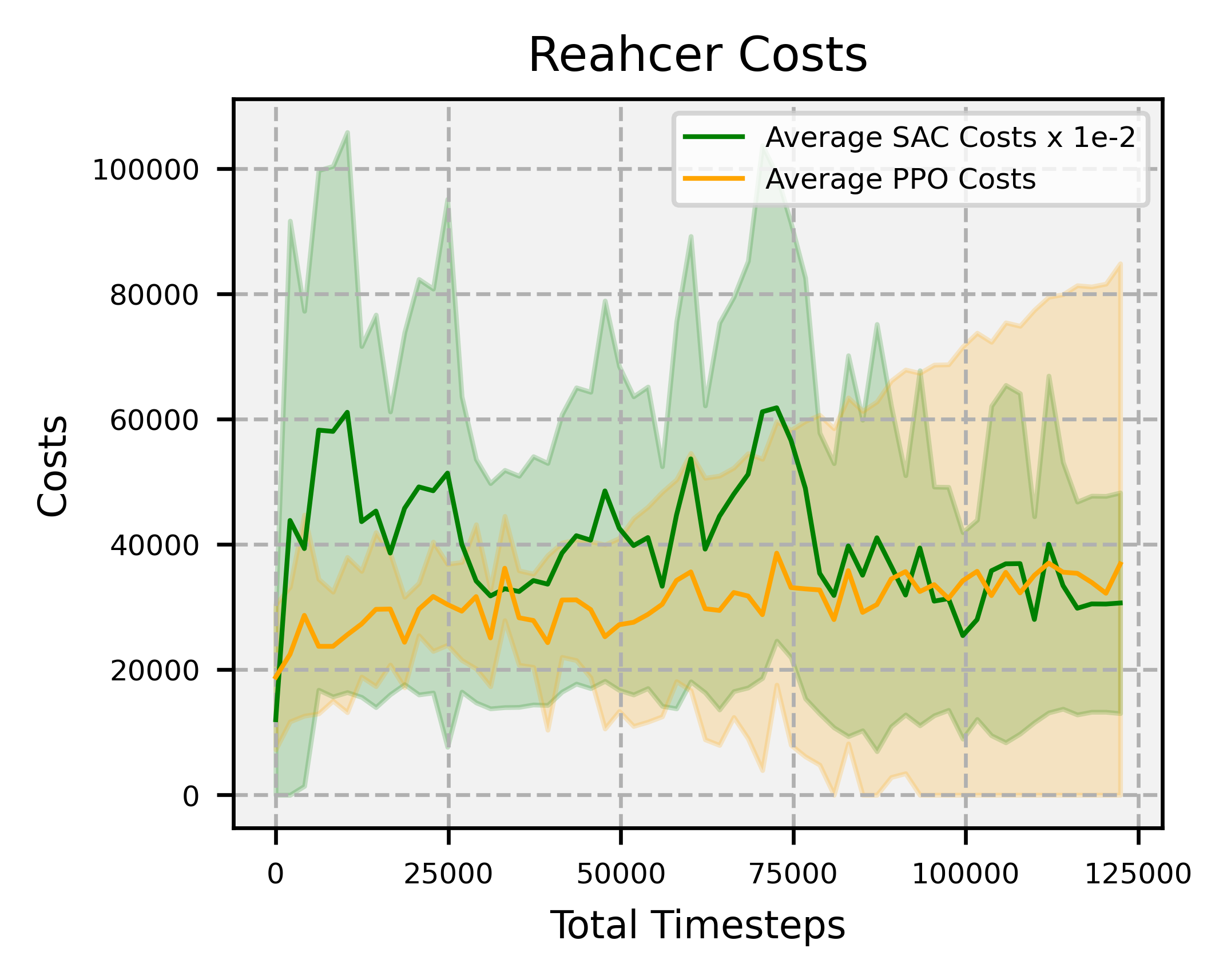
Overview: significantly faster convergence and lower variance across random seeds, outperforming SAC and PPO by factors of at least 74 and 2, respectively.
Conclusion
Contribution
- Global policy.
- Efficiency from direct derivatives.
- Lower memory footprint via continuous-time adjoints.
Caveats
- Requires full dynamics information.
- No ability to introduce smoothing through noise.
- Only quadratic control constraints and no state constraints.